One of the perennial talking points in the Python packaging discourse is that
it’s unnecessarily difficult to create a simple, single-file binary that you
can hand to users.
This complaint is understandable. In most other programming languages, the
first thing you sit down to do is to invoke the compiler, get an executable,
and run it. Other, more recently created programming languages — particularly
Go and Rust — have really excellent toolchains for doing this which eliminate a
lot of classes of error during that build-and-run process. A single,
dependency-free, binary executable file that you can run is an eminently
comprehensible artifact, an obvious endpoint for “packaging” as an endeavor.
While Rust and Go are producing these artifacts as effectively their only
output, Python has such a dizzying array of tooling complexity that even
attempting to describe “the problem” takes many thousands of
words and
one may not ever even get around to fully describing the complexity of the
issues involved in the course of those words. All the more understandable,
then, that we should urgently add this functionality to Python.
A programmer might see Python produce wheels and virtualenvs which can break
when anything in their environment changes, and see the complexity of that
situation. Then, they see Rust produce a statically-linked executable which
“just works”, and they see its toolchain simplicity. I agree that this
shouldn’t be so hard, and some of the architectural decisions that make this
difficult in Python are indeed unfortunate.
But then, I think, our hypothetical programmer gets confused. They think that
Rust is simple because it produces an executable, and they think Python’s
complexity comes from all the packaging standards and tools. But this is not
entirely true.
Python’s packaging complexity, and indeed some of those packaging standards,
arises from the fact that it is often used as a glue language. Packaging
pure Python is really not all that hard. And although the tools aren’t
included with the language and the DX isn’t as smooth, even packaging pure
Python into a single-file executable is pretty
trivial.
But almost nobody wants to package a single pure-python script. The whole
reason you’re writing in Python is because you want to rely on an enormous
ecosystem of libraries, and some low but critical percentage of those libraries
include things like their own statically-linked copies of OpenSSL or a few
megabytes of FORTRAN code with its own extremely finicky build system you don’t
want to have to interact with.
When you look aside to other ecosystems, while Python still definitely has some
unique challenges, shipping Rust with a ton of FFI, or Go with a bunch of Cgo
is substantially more complex than the default out-of-the-box single-file “it
just works” executable you get at the start.
Still, all things being equal, I think single-file executable builds would be
nice for Python to have as a building block. It’s certainly easier to produce
a package for a platform if your starting point is that you have a
known-good, functioning single-file executable and you all you need to do is
embed it in some kind of environment-specific envelope. Certainly if what you
want is to copy a simple microservice executable into a container image, you
might really want to have this rather than setting up what is functionally a
full Python development environment in your Dockerfile. After team-wide
philosophical debates over what virtual environment manager to use, those
Golang Dockerfiles that seem to be nothing but the following 4 lines are
really appealing:
| FROM golang
COPY *.go ./
RUN go build -o /app
ENTRYPOINT ["/app"]
|
All things are rarely equal, however.
The issue that we, as a community, ought to be trying to address with build
tools is to get the software into users’ hands, not to produce a specific
file format. In my opinion, single-file binary builds are not a great tool for
this. They’re fundamentally not how people, even quite tech-savvy programming
people, find and manage their tools.
A brief summary of the problems with single-file distributions:
- They’re not discoverable. A single file linked on your website will not be
found via something like
brew search, apt search, choco search or
searching in a platform’s GUI app store’s search bar.
- They’re not updatable. People expect their system package manager to update
stuff for them. Standalone binaries might add their own updaters, but now
you’re shipping a whole software-update system inside your binary. More
likely, it’ll go stale forever while better-packaged software will be
updated and managed properly.
- They have trouble packaging resources. Once you’ve got your code stuffed
into a binary, how do you distribute images, configuration files, or other
data resources along with it? This isn’t impossible to solve, but in
other programming languages which do have a great single-file binary
story, this problem is typically solved by third party
tooling which, while it might work
fine, will still generally exist in multiple alternative
forms which adds its own complexity.
So while it might be a useful building-block that simplifies those annoying
container builds a lot, it hardly solves the problem comprehensively.
If we were to build a big new tool, the tool we need is something that
standardizes the input format to produce a variety of different complex,
multi-file output formats, including things like:
- deb packages (including uploading to PPA archives so people can add an apt
line; a manual
dpkg -i has many of the same issues as a single file)
- container images (including the upload to a registry so that people can
"$(shuf -n 1 -e nerdctl docker podman)" pull or FROM it)
- Flatpak apps
- Snaps
- macOS apps
- Microsoft store apps
- MSI installers
- Chocolatey / NuGet packages
- Homebrew formulae
In other words, ask yourself, as a user of an application, how do you want
to consume it? It depends what kind of tool it is, and there is no
one-size-fits-all answer.
In any software ecosystem, if a feature is a building block which doesn’t fully
solve the problem, that is an issue with the feature, but in many cases,
that’s fine. We need lots of building blocks to get to full solutions. This
is the story of open source.
However, if I had to take a crack at summing up the infinite-headed hydra of
the Problem With Python Packaging, I’d put it like this:
Python has a wide array of tools which can be used to package your Python
code for almost any platform, in almost any form, if you are sufficiently
determined. The problem is that the end-to-end experience of shipping an
application to end users who are not Python programmers for any
particular platform has a terrible user experience. What we need are more
holistic solutions, not more building blocks.
This makes me want to push back against this tendency whenever I see it, and to
try to point towards more efficient ways to achieving a good user experience,
with the relatively scarce community resources at our collective disposal.
Efficiency isn’t exclusively about ideal outcomes, though; it’s the
optimization a cost/benefit ratio. In terms of benefits, it’s relatively low,
as I hope I’ve shown above.
Building a tool that makes arbitrary Python code into a fully self-contained
executable is also very high-cost, in terms of community effort, for a bunch of
reasons. For starters, in any moderately-large collection of popular
dependencies from PyPI, at least a few of them are going to want to find their
own resources via __file__, and you need to hack in a way to find those,
which is itself error prone. Python also expects dynamic linking in a lot of
places, and messing around with C linkers to change that around is a complex
process with its own huge pile of failure modes. You need to do this on
pre-existing binaries built with options you can’t necessarily control,
because making everyone rebuild all the binary wheels they find on PyPI is a
huge step backwards in terms of exposing app developers to confusing
infrastructure complexity.
Now, none of this is impossible. There are even existing
tools to do some of the
scarier low-level parts of these
problems. But one of the reasons that all the existing tools for doing similar
things have folk-wisdom reputations and even official
documentation
expecting constant pain is that part of the project here is conducting a full
audit of every usage of __file__ on PyPI and replacing it with some
resource-locating API which we haven’t even got a mature version of yet.
Whereas copying all the files into the right spots in an archive file that can
be directly deployed to an existing platform is tedious, but only moderately
challenging. It usually doesn’t involve fundamentally changing how the code
being packaged works, only where it is placed.
To the extent that we have a choice between “make it easy to produce a
single-file binary without needing to understand the complexities of binaries”
or “make it easy to produce a Homebrew formula / Flatpak build / etc without
the user needing to understand Homebrew / Flatpak / etc”, we should always
choose the latter.
If this is giving you déjà vu, I’ve gestured at this general concept more
vaguely in a few places, including tweeting about it in 2019, saying
vaguely similar stuff:
Everything I’ve written here so far is debatable.
You can find that debate both in replies to that original tweet and in various
other comments and posts elsewhere that I’ve grumbled about this. I still
don’t agree with that criticism, but there are very clever people working on
complex tools which are slowly gaining
popularity and might be making the
overall packaging situation better.
So while I think we should in general direct efforts more towards integrating
with full-featured packaging standards, I don’t want to yuck anybody’s yum when
it comes to producing clean single-file executables in general. If you want to
build that tool and it turns out to be a more useful building block than I’m
giving it credit for, knock yourself out.
However, in addition to having a comprehensive write-up of my previously-stated
opinions here, I want to impart a more concrete, less debatable issue. To wit:
single-file executables as a distribution mechanism, specifically on macOS
is not only sub-optimal, but a complete waste of time.
Late last year, Hynek wrote a great
post about his desire for, and
experience of, packaging a single-file binary for multiple platforms. This
should serve as an illustrative example of my point here. I don’t want to pick
on Hynek. Prominent Python programmers wish for this all the
time.. In
fact, Hynek also did the thing I said is a good idea here, and did, in fact,
create a Homebrew tap, and that’s the
one the README
recommends.
So since he kindly supplied a perfect case-study of the contrasting options,
let’s contrast them!
The first thing I notice is that the Homebrew version is Apple Silicon native,
whereas the single-file binary is still x86_64, as the brew build and test
infrastructure apparently deals with architectural differences (probably pretty
easy given it can use Homebrew’s existing Python build) but the more
hand-rolled PyOxidizer
setup
builds only for the host platform, which in this case is still an Intel mac
thanks to GitHub dragging their feet.
The second is that the Homebrew version runs as I expect it to. I run
doc2dash in my terminal and I see Usage: doc2dash [OPTIONS] SOURCE, as I
should.
So, A+ on the Homebrew tap. No notes. I did not have to know anything about
Python being in the loop at all here, it “just works” like every Ruby, Clojure,
Rust, or Go tool I’ve installed with the same toolchain.
Over to the single-file brew-less version.
Beyond the architecture being emulated and having to download Rosetta2, I
have to note that this “single file” binary already comes in a zip file, since
it needs to include the license in a separate file. Now that it’s
unarchived, I have some choices to make about where to put it on my $PATH.
But let’s ignore that for now and focus on the experience of running it. I
fire up a terminal, and run cd Downloads/doc2dash.x86_64-apple-darwin/ and
then ./doc2dash.
Now we hit the more intractable problem:
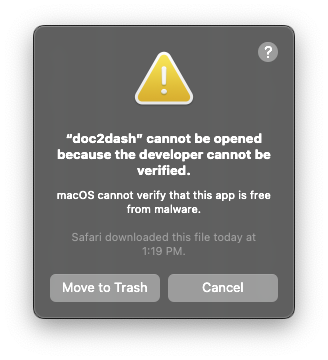
The executable does not launch because it is neither code-signed nor
notarized. I’m not going to go through the actual demonstration here, because
you already know how annoying this is,
and also, you can’t actually do it.
Code-signing is more or less fine. The codesign tool will do its thing, and
that will change the wording in the angry dialog box from something about an
“unidentified developer” to being “unable to check for malware”, which is not
much of a help. You still need to notarize it, and notarization can’t work.
macOS really wants your executable code to be in a bundle (i.e., an App) so
that it can know various things about its provenance and structure. CLI tools
are expected to be in the operating system, or managed by a tool like brew
that acts like a sort of bootleg secondary operating-system-ish thing and knows
how to manage binaries.
If it isn’t in a bundle, then it needs to be in a platform-specific .pkg
file, which is installed with the built-in Installer app. This is because
apple cannot notarize a stand-alone binary executable file.
Part of the notarization process involves stapling an external “notarization
ticket” to your code, and if you’ve only got a single file, it has nowhere to
put that ticket. You can’t even submit a stand-alone binary; you have to
package it in a format that is legible to Apple’s notarization service, which
for a pure-CLI tool, means a
.pkg.
What about corporate distributions of proprietary command-line tools, like the
1Password CLI? Oh look, their official instructions also tell you to use
their Homebrew formula
too. Homebrew
really is the standard developer-CLI platform at this point for macOS. When
1Password distributes stuff outside of Homebrew, as with their beta
builds, it’s stuff
that lives in a .pkg as well.
It is possible to work around all of this.
I could open the unzipped file, right-click on the CLI tool, go to “Open”, get
a subtly differently worded error
dialog, like this…
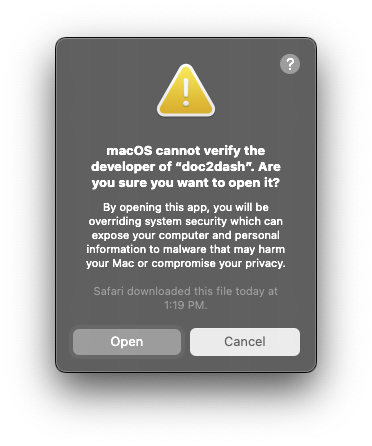
…watch it open Terminal for me and then exit, then wait multiple seconds for
it to run each time I want to re-run it at the command line. Did I mention
that? The single-file option takes 2-3 seconds doing who-knows what (maybe
some kind of security check, maybe pyoxidizer overhead, I don’t know) but the
Homebrew version starts imperceptibly instantly.
Also, I then need to manually re-do this process in the GUI every time I want
to update it.
If you know about the magic of how this all actually works, you can also do
xattr -d com.apple.quarantine doc2dash by hand, but I feel like xattr -d is
a step lower down in the user-friendliness hierarchy than python3 -m pip
install, and not only because making a habit of clearing quarantine
attributes manually is a little like cutting the brake lines on Gatekeeper’s
ability to keep out malware.
But the point of distributing a single-file binary is to make it “easy” for
end users, and is explaining gatekeeper’s integrity verification accomplishing
that goal?
Apple’s effectively mandatory code-signing verification on macOS is far out
ahead of other desktop platforms right now, both in terms of its security and
in terms of its obnoxiousness. But every mobile platform is like this, and I
think that as everyone gets more and more
panicked
about malicious interference with software delivery, we’re going to see more
and more official requirements that software must come packaged in one of
these containers.
Microsoft will probably fix their absolute trash-fire of a codesigning
system
one day too. I predict that something vaguely like this will eventually even
come to most Linux distributions. Not necessarily a prohibition on individual
binaries like this, or like a GUI launch-prevention tool, but some sort of
requirement imposed by the OS that every binary file be traceable to some sort
of package, maybe enforced with some sort of annoying
AppArmor profile if you don’t do it.
The practical, immediate message today is: “don’t bother producing a
single-file binary for macOS users, we don’t want it and we will have a hard
time using it”. But the longer term message is that focusing on creating
single-file binaries is, in general, skating to where the puck used to be.
If we want Python to have a good platform-specific distribution mechanism for
every platform, so it’s easy for developers to get their tools to users without
having to teach all their users a bunch of nonsense about setuptools and
virtualenvs first, we need to build that, and not get hung up on making a
single-file executable packer a core part of the developer experience.
Thanks very much to my patrons for their support of
writing like this, and software
like
these.
Oh, right. This is where I put the marketing “call to action”. Still getting
the hang of these.
Did you enjoy this post and want me to write more like it, and/or did you
hate it and want the psychological leverage and moral authority to tell me to
stop and do something else? You can sign up
here!




